Hadoop: Описание, архитектура, экосистема, компоненты
Что такое Hadoop?
Apache Hadoop — это программная среда с открытым исходным кодом, используемая для разработки приложений обработки данных, которые выполняются в распределенной вычислительной среде.
Приложения, созданные с помощью HADOOP, выполняются на больших массивах данных, распределенных по кластерам компьютеров. Товарные компьютеры дешевы и широко доступны. Они в основном полезны для достижения большей вычислительной мощности при низких затратах.
Подобно данным, хранящимся в локальной файловой системе персонального компьютера, в Хадуп данные хранятся в распределенной файловой системе, которая называется Hadoop Distributed File System. Модель обработки основана на концепции «локальности данных», в соответствии с которой вычислительная логика отправляется на узлы кластера (сервера), содержащие данные. Эта вычислительная логика — не что иное, как скомпилированная версия программы, написанной на языке высокого уровня, таком как Java. Такая программа обрабатывает данные, хранящиеся в Hadoop HDFS.
Экосистема и компоненты Hadoop
На приведенной ниже диаграмме показаны различные компоненты экосистемы Hadoop
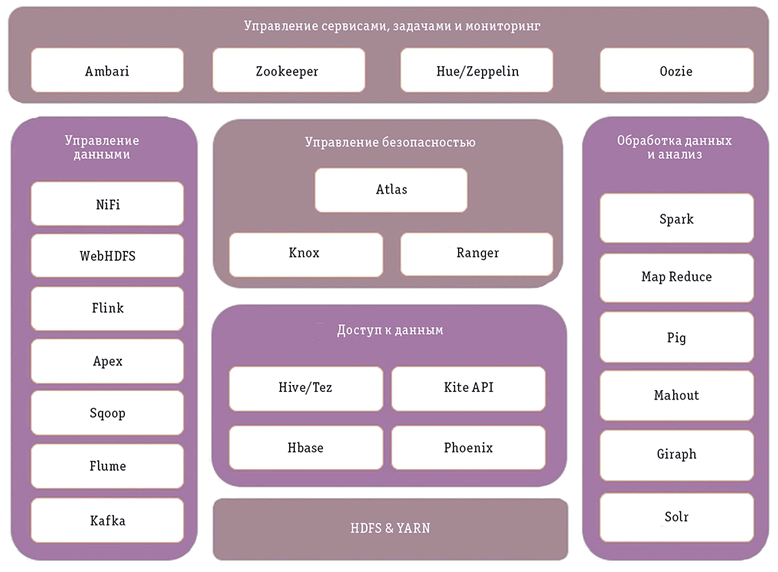
Источник: osp.ru
Из чего состоит Hadoop
Hadoop состоит из распределенной файловой системы (HDFS) и механизма обработки (MapReduce), которые работают вместе для обеспечения распределенного хранения и обработки больших массивов данных. Ниже представлена концептуальная архитектура Hadoop:
HDFS: HDFS — это распределенная файловая система, предназначенная для хранения и управления большими массивами данных на нескольких машинах. Она разбивает данные на более мелкие фрагменты, называемые «блоками», и распределяет их между узлами кластера. Это позволяет параллельно обрабатывать данные и обеспечивает их высокую доступность и отказоустойчивость.
NameNode: NameNode — это главный узел, который управляет метаданными файловой системы, включая расположение файлов, каталогов и блоков. Он поддерживает сопоставление файлов с узлами, на которых они хранятся, и координирует доступ к файлам.
Узел данных: DataNode — это рабочие узлы, которые хранят фактические блоки данных. Они получают запросы на чтение и запись от клиентов и взаимодействуют с NameNode для обеспечения согласованности и репликации данных.
MapReduce: MapReduce — это модель программирования и механизм обработки, позволяющий распределенно обрабатывать данные в кластере Hadoop. Он предназначен для обработки крупномасштабных данных путем разбиения задач на более мелкие подзадачи и распределения их по нескольким узлам.
JobTracker: JobTracker — это главный узел, который управляет обработкой заданий MapReduce. Он распределяет задания по узлам кластера и следит за их выполнением. Он также управляет планированием заданий и распределением ресурсов.
TaskTracker: TaskTracker — это рабочий узел, выполняющий задания MapReduce. Он получает задания от JobTracker и выполняет их локально на узле. Он также сообщает о ходе выполнения и статусе задания обратно JobTracker.
Вместе HDFS и MapReduce образуют основные компоненты Hadoop, обеспечивающие распределенное хранение и обработку больших массивов данных. Другие компоненты, такие как YARN (Yet Another Resource Negotiator) и HBase (база данных NoSQL), создаются поверх Hadoop для обеспечения дополнительной функциональности и поддержки различных типов рабочих нагрузок по обработке данных.
Apache Hadoop состоит из двух подпроектов:
- Hadoop MapReduce: MapReduce — это вычислительная модель и программная основа для написания приложений, которые запускаются на Hadoop. Эти программы MapReduce способны параллельно обрабатывать огромные данные на больших кластерах вычислительных узлов.
- HDFS (распределенная файловая система Hadoop): HDFS заботится о хранении данных в приложениях Hadoop. Приложения MapReduce потребляют данные из HDFS. HDFS создает несколько копий блоков данных и распределяет их по вычислительным узлам кластера. Такое распределение обеспечивает надежные и чрезвычайно быстрые вычисления.
Хотя Хадуп наиболее известен благодаря MapReduce и его распределенной файловой системе HDFS, этот термин также используется для обозначения целого семейства родственных проектов, которые относятся к распределенным вычислениям и обработке крупномасштабных данных. Другие проекты, связанные с Hadoop в Apache, включают Hive, HBase, Mahout, Sqoop, Flume и ZooKeeper.
Архитектура Hadoop
Hadoop имеет архитектуру Master-Slave для хранения данных и распределенной обработки данных с использованием методов MapReduce и HDFS.
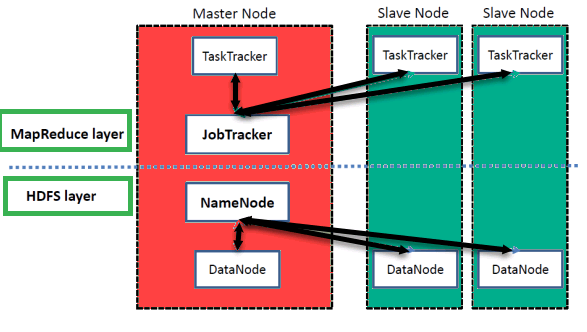
NameNode
NameNode представляет каждый файл и каталог, который используется в пространстве имен.
DataNode
DataNode помогает управлять состоянием узла HDFS и позволяет взаимодействовать с блоками
MasterNode
Ведущий узел позволяет проводить параллельную обработку данных с помощью Hadoop MapReduce.
Slave node
Ведомые узлы — это дополнительные машины в кластере Hadoop, которые позволяют хранить данные для проведения сложных вычислений. Более того, все ведомые узлы поставляются с Task Tracker и DataNode. Это позволяет синхронизировать процессы с NameNode и Job Tracker соответственно.
В Hadoop ведущая или ведомая система может быть создана в облаке или на месте.
Особенности Хадуп
Подходит для анализа больших данных
Поскольку большие данные, как правило, распределены и неструктурированы по своей природе, кластеры HADOOP лучше всего подходят для анализа больших данных. Поскольку на вычислительные узлы поступает логика обработки (а не фактические данные), потребляется меньшая пропускная способность сети. Эта концепция называется концепцией локальности данных, которая помогает повысить эффективность приложений на базе Hadoop.
Масштабируемость
Кластеры HADOOP могут быть легко масштабированы в любой степени путем добавления дополнительных узлов кластера, что позволяет увеличивать объем Больших Данных. Кроме того, масштабирование не требует внесения изменений в логику приложения.
Отказоустойчивость
В экосистеме HADOOP предусмотрена возможность репликации входных данных на другие узлы кластера. Таким образом, в случае отказа одного из узлов кластера обработка данных может продолжаться с использованием данных, хранящихся на другом узле кластера.
Топология сети в Hadoop
Топология (расположение) сети влияет на производительность кластера Hadoop, когда размер кластера Hadoop увеличивается. Помимо производительности, необходимо также позаботиться о высокой доступности и обработке отказов. Для того чтобы достичь этого Hadoop, при формировании кластера используется топология сети.
Как правило, пропускная способность сети является важным фактором, который необходимо учитывать при формировании любой сети. Однако, поскольку измерение пропускной способности может быть затруднено, в Hadoop сеть представляется в виде дерева, а расстояние между узлами этого дерева (количество хопов) рассматривается как важный фактор при формировании кластера Hadoop. Здесь расстояние между двумя узлами равно сумме их расстояний до ближайшего общего предка.
Кластер Hadoop состоит из центра обработки данных, стойки и узла, который фактически выполняет задания. Здесь центр обработки данных состоит из стоек, а стойка — из узлов. Пропускная способность сети, доступная процессам, меняется в зависимости от местоположения процессов. То есть, доступная пропускная способность становится меньше по мере удаления от…
- Процессы на одном узле
- Разные узлы на одной стойке
- Узлы на разных стойках одного центра обработки данных
- Узлы в разных центрах обработки данных
Хадуп — плюсы и минусы
Вот некоторые плюсы и минусы использования Hadoop:
Плюсы
- Масштабируемость: Хадум легко масштабируется, позволяя организациям хранить и обрабатывать большие объемы данных.
- Экономическая эффективность: Hadoop работает на аппаратном обеспечении и имеет открытый исходный код, что делает его экономически эффективным для организаций, которым необходимо хранить и обрабатывать большие объемы данных.
- Отказоустойчивость: Hadoop спроектирован таким образом, чтобы мягко справляться с аппаратными и программными сбоями, обеспечивая высокую доступность данных.
- Гибкость: Hadoop может работать с различными источниками и форматами данных, включая структурированные, полуструктурированные и неструктурированные данные.
- Поддержка сообщества: Hadoop имеет большое и активное сообщество разработчиков и пользователей, предоставляющее пользователям поддержку и ресурсы.
Минусы
- Сложность: Hadoop может быть сложным в настройке и управлении, требуя специальных навыков и знаний.
- Производительность: Hadoop может быть недостаточно эффективен для обработки и анализа данных в режиме реального времени, поскольку он оптимизирован для пакетной обработки.
- Безопасность данных: распределенная архитектура Hadoop может затруднить обеспечение безопасности данных, поскольку данные хранятся на нескольких узлах.
- Инструментарий: Инструментарий Hadoop для ввода, обработки и анализа данных может быть разрозненным, что затрудняет выбор подходящего инструмента для работы.
- Кривая обучения: Освоение Hadoop может занять много времени и потребовать значительных инвестиций в обучение и ресурсы.
Hadoop и Интернет вещей (IoT)
Hadoop может стать важной вспомогательной технологией для проектов Интернета вещей (IoT). В типичном приложении IoT сеть датчиков или других интеллектуальных устройств постоянно отправляет данные о текущем состоянии на платформу, которая анализирует данные, обрабатывает то, что имеет значение, и автоматически направляет соответствующие действия (например, отключение машины, которой грозит перегрев). Данные датчиков и устройств также сохраняются для дополнительной аналитики.
Программы IoT часто производят такие объемы и типы данных, с которыми предприятия никогда раньше не имели дела. Например, интеллектуальная заводская система может производить миллионы показаний датчиков каждый день. Организации, которые занимаются IoT, могут быть быстро втянуты в мир больших данных. Hadoop может стать спасательным кругом для эффективного хранения, обработки и управления новыми источниками данных.
Является ли Hadoop эффективным использованием ресурсов?
Как только организации определяют, что Хадуп даст им возможность работать с большими данными, они часто начинают задаваться вопросом, является ли этот способ эффективным. В большинстве случаев ответ положительный. Hadoop также часто оказывается более экономичным и ресурсоэффективным, чем методы, которые обычно используются для обслуживания корпоративных хранилищ данных (EDW).
Хадуп является эффективной и экономичной платформой для больших данных, поскольку он работает на серверах с подключенным хранилищем, что является менее дорогостоящей архитектурой, чем выделенная сеть хранения данных (SAN). Товарные кластеры Hadoop также очень масштабируемы, что очень важно, поскольку программы работы с большими данными имеют тенденцию увеличиваться по мере того, как пользователи приобретают опыт и повышают их ценность для бизнеса.
Hadoop не только делает работу с большими данными экономически эффективной, но и снижает затраты на поддержание существующего корпоративного хранилища данных. Это происходит потому, что основные задачи извлечения-транспортировки-загрузки (ETL), которые обычно выполняются на оборудовании EDW, могут быть перегружены для выполнения на более дешевых кластерах Hadoop. ETL требует большого количества циклов обработки, поэтому эффективнее использовать ресурсы, чтобы не выполнять их на высокопроизводительных машинах, на которых размещаются корпоративные хранилища данных.
Стоимость и ценность использования Hadoop зависит от сценариев использования, конкретных используемых инструментов и конфигураций, а также от объема данных в среде. Вспомогательные инструменты и решения, используемые наряду с основной технологией Hadoop, оказывают огромное влияние на стоимость разработки и поддержки среды. Более глубокое понимание экосистемы Hadoop представлено в следующем разделе.
Бизнес-обоснование для Hadoop
Бизнес-обоснование для Хадуп зависит от ценности информации. Hadoop может сделать больше информации доступной, он может анализировать больше информации для поддержки принятия решений, и он может сделать информацию более ценной, анализируя ее в режиме реального времени. В отличие от технологий бизнес-анализа более раннего поколения, Хадуп помогает организациям разобраться как в структурированных, так и в неструктурированных данных. Hadoop позволяет получать новые сведения, поскольку он способен обрабатывать новые типы данных, такие как потоки социальных сетей и данные с датчиков. Многие организации нашли пользу в Hadoop, используя его для лучшего понимания своих клиентов, конкурентов, цепочек поставок, рисков и возможностей.
Hadoop может помочь вам воспользоваться информацией из прошлого, настоящего и будущего. Многие считают, что большие данные в основном направлены на анализ исторической информации, которая может быть или не быть актуальной в текущих условиях. Хотя решения на основе больших данных часто проводят исторический анализ для составления прогнозов и рекомендаций, они также предоставляют возможность анализировать и действовать на основе данных о текущем состоянии в режиме реального времени. Например, Hadoop является основой для рекомендательных механизмов, которые используют некоторые розничные компании электронной коммерции, чтобы предлагать товары, пока клиенты просматривают их сайты. Рекомендации основаны на анализе истории предыдущих покупок конкретного клиента, информации о том, что другие клиенты приобрели вместе с просматриваемым товаром, а также о текущих тенденциях путем анализа настроений, полученных из потоков социальных сетей. Эти многочисленные источники данных должны быть обработаны, проанализированы и преобразованы в полезную информацию за то короткое время, пока клиент находится на странице. Hadoop делает все это возможным, и в результате розничные компании сообщают о повышении продаж от 2 до 20 процентов. Когда продажа совершена, Hadoop помогает финансовым учреждениям обнаружить и предотвратить потенциальное мошенничество с кредитными картами в режиме реального времени.
Решения на базе Hadoop также могут учитывать текущие и исторические данные, чтобы направлять будущую деятельность, например, составлять рекомендации по планированию ассортимента для розничной торговли или разрабатывать предиктивные графики технического обслуживания производственного оборудования и других активов.
Что заменяет Hadoop?
Hadoop обычно используется для поддержки принятия более эффективных решений. Поэтому он часто дополняет уже используемые системы обработки данных и отчетности, а не заменяет их. Например, Tableau — это популярный инструмент бизнес-аналитики, который организации используют для обработки и визуализации различных данных. Tableau поддерживает Hadoop и предоставляет еще один вариант вывода анализа данных на основе Хадуп. Excel также может обрабатывать данные, импортированные из Hadoop, однако более сложные решения, ориентированные на большие данные, поддерживают больше возможностей. Экосистема Hadoop постоянно расширяется за счет новых решений, помогающих пользователям использовать преимущества Hadoop новыми способами.
Hadoop действительно заменяет необходимость иметь кластеры специализированных высокопроизводительных компьютеров, которые поддерживаются большими командами технических специалистов и специалистов по анализу данных для превращения данных в полезную информацию. Hadoop является альтернативой использованию структур баз данных с массивно-параллельной обработкой (MPP), которые, как правило, создаются на заказ и стоят дорого. Hadoop также может заменить традиционные ИТ-архитектуры, основанные на «силосах», или, по крайней мере, обеспечить взаимодействие «силосов» и служить единым источником данных.
Проблемы, которые решает Hadoop
Hadoop решает фундаментальную проблему обработки больших наборов структурированных и неструктурированных данных, которые поступают из разрозненных источников и находятся в разных системах. Более конкретно, Hadoop решает проблемы масштаба, задержки и полноты при работе с большими наборами данных.
Масштаб
Hadoop позволяет обрабатывать большие массивы данных на обычных компьютерах. Он также решает проблему получения точного, единого представления структурированных и неструктурированных данных, хранящихся в нескольких системах.
Латентность
Hadoop может обрабатывать большие массивы данных гораздо быстрее, чем традиционные методы, поэтому организации могут действовать на основе данных, пока они еще актуальны. Например, рекомендательные системы предлагают дополнительные товары или специальные предложения в режиме реального времени. В прошлом организации могли составлять отчет о покупках клиентов, анализировать результаты, а затем через несколько дней или недель отправлять повторное письмо с предложением тех же дополнительных товаров. Устранение задержки также имеет огромную ценность при мониторинге сетевых вторжений, финансовых махинаций и других угроз.
Комплексность
Одним из отличий Hadoop является его способность обрабатывать различные типы данных. Помимо традиционных структурированных данных, которые иногда называют данными в состоянии покоя, Hadoop может сортировать и обрабатывать данные в движении, такие как данные с датчиков, данные о местоположении, каналы социальных сетей, метаданные из видео и систем контактов с клиентами. Он также может выполнять анализ данных потока кликов. Всеобъемлющий характер данных создает большую наглядность и более глубокое понимание того, что изучается.
Эти характеристики Hadoop также выражаются как «три V» — объем, скорость и разнообразие (англ: volume, velocity, and variety).